
HyFlex Tutorial
- Quick Start
- Important!
- Software Structure
- The Time Limit
- The Memory of Solutions
- Four Classes of Low Level Heuristic
- 'Depht of Search' and 'Intensity of Mutation'
- HyFlex Software Documentation (API Document)
Quick Start
This section is intended to enable developers to quickly get started on programming a hyper-heuristic.The software can either be run using Java from the command line, or by importing the files into a Java IDE such as Eclipse.
In either case, put the Examples Package in the same directory as the chesc.jar file.
If using an IDE (such as Eclipse), when creating a new "Java Project", we recommend to specify "Use project folder as root for sources and class files" rather than "Create separate folders ..". Using the second option creates 'src' and 'bin' folders for the source and class files.
It is likely not to be very important, but we use the first option, and so the tutorial is written from that point of view. Also we may find it easier to solve technical issues with the software if your set-up is the same as ours.
Compile the Examples Package so you can run our examples. If you are running java from the command line, use the following command (Important! The classpath must be set so that the classes within the Jar file can be used).
javac -cp chesc.jar Examples/*.java
In Eclipse, if the project will not compile (because it cannot recognise a lot of different class names) then it is probably the case that you have not manually added the JAR file to the build path. To do this in Eclipse, right click the project folder on the left of the screen, click 'build path' and then 'add external archives'
Run the class Examples.ExampleRun1.java. From the command line, we set the classpath so we can use the jar file:
- (Windows) java -cp .; chesc.jar Examples.ExampleRun1
- (Linux) java -cp .: chesc.jar Examples.ExampleRun1
At this point, it is advisable to study the ExampleRun1 class. Comments in the code explain each section in detail, but a summary of the steps is given here.
- Create a Problem Domain object
- Create a Hyper-Heuristic object
- Load a problem instance
- Set a time limit
- Tell the Hyper-Heuristic which problem it is to solve, by giving it the reference to the Problem Domain object
- Run the Hyper-Heuristic
- Print the best solution found within the time limit
ExampleHyperHeuristic2.java shows a more complex hyper-heuristic, which uses ten solutions for the search instead of just one.
ExampleHyperHeuristic3.java shows a modified version of ExampleHyperHeuristic2.java, which makes use of the fact that the low level heuristics are pre-classified into four categories.
ExampleRun2.java provides example code to test more than one hyper-heuristic in one run, and how to test them on more than one Problem Domain. It also shows how to obtain some statistics from the hyper-heuristics, to analyse their performance.
Important!
Please update your java jdk version to at least 1.6.20.The 'Personnel Scheduling' class can sometimes require more than the default JVM memory, so it is important to assign more JVM memory when running this software. See below for the details of how to do this. In the example below we are setting the memory to 512m. However, for the competition we will extend this value to that required for a successful run of the competition entries.
- Command Line: java -Xmx512m ExampleRun1
- Eclipse IDE: In the 'Run Configurations...' menu, click the 'Arguments' tab, and copy "-Xmx512m" into the 'VM Arguments' box.
[Top]
Software Structure
HyperHeuristic
Your hyper-heuristic strategy will be implemented as a subclass of the abstract class illustrated in Figure 1 (see also . In order to understand how to create a hyper-heuristic within the HyFlex software, we have provided three example HyperHeuristic classes, and two example classes which run the hyper-heuristics. While most of the methods usable by your hyper-heuristic object during a run are explained in the ExampleHyperHeuristic[1-3].java classes, the full list can be found in the Javadoc for the HyperHeuristic abstract class and the ProblemDomain abstract class.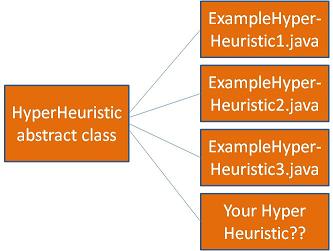
Each problem domain contains
a number of
low level heuristics. It is
the job of the hyper-heuristic strategy to intelliently
control the use
of these low level heuristics. The problem domains
supplied in the
HyFlex framework are implemented as subclasses of the
ProblemDomain
abstract class, as shown in Figure 2.
This
means
that there is a common interface through which your
hyper-heuristic can
communicate with the low level heuristics of each problem
domain. All
problem domains are implemented as minimisation problems.
A lower
objective function value is always better in HyFlex.
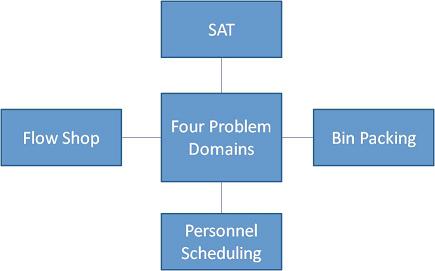
Running your HyperHeuristic
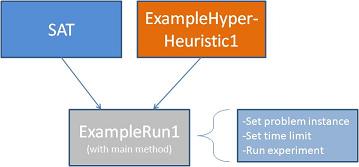
To run a hyper-heuristic strategy, you must implement a subclass of the HyperHeuristic abstract class, create an object of that subclass, and create an object of a particular problem domain. You then give the ProblemDomain object to your HyperHeuristic object, and call the run() method of the HyperHeuristic object (see Figure 3).
[Top]
Time Limit
It is important to note that every call by a hyper-heuristic to its hasTimeExpired() method records the best fitness function value found so far by the hyper-heuristic. This is a mechanism which ensures that only solutions found within the time limit are used for scoring, and it is intended to ensure that there is NO BENEFIT to exceeding the time limit. Every time a low level heuristic is applied with ProblemDomain.applyHeuristic(), the ProblemDomain object updates the "best fitness found so far". However, this is ONLY recorded for scoring purposes when the hasTimeExpired() method is called. For this reason, it is beneficial to put a hasTimeExpired() checks into your hyper-heuristic code at every point that the solution could have been improved. Ideally, for many hyper-heuristics, this will be after every application of a low level heuristic, rather than at the end of each iteration (every iteration may contain multiple low level heuristic applications).In the extreme case, if there are no calls to the hasTimeExpired() method, then the hyper-heuristic will iterate for as long as the user wants. It could obtain a much better solution than the other competitors by using much more time. However, this solution will never be recorded for scoring purposes because the hasTimeExpired() method was never called. While we have taken these reasonable steps to negate any advantage from exceeding the time limit, we admit that we may not have thought of everything! Therefore we issue this warning: attempting to obtain advantage by significantly exceeding the time limit is definitely not in the spirit of the competiton, and will result in disqualification.
The Memory of Solutions
An important feature of the software is the flexibility to perform a single point search or to work with a population of solutions. Specifically, each problem domain object has a customisable memory of solutions, which can be manipulated by the user. Solutions can be copied to other indices in full, overwrite other solutions, or can be initialised with a random new solution.The basic use of this memory can be seen in ExampleHyperHeuristic1.java. It maintains the current solution in index 0 of the memory array. A low level heuristic is applied to the solution at index 0, and the resulting solution is placed into index 1 of the memory. If the 'move' is accepted, then the solution at index 1 is copied into index 0, so it becomes the current solution.
The default memory size is 2, which is sufficient for a standard single point search. If the operation of the hyper-heuristic requires more solutions to be stored (for example, for a population based approach), then your HyperHeuristic object must modify the number of solutions that can be stored in memory with the ProblemDomain.setMemorySize() method.
ExampleHyperHeuristic2.java shows how to implement and use a larger memory, of ten solutions.
[Top]
Four Classes of Low Level Heuristic
As the aim of the competition is to develop a general hyper-heuristic, which controls a set of heuristics, we hide the exact functionality of the low level heuristics. However, we do classify the heuristics into four broad classes: local search, mutation, ruin-recreate, and crossover. This information can be used to create potentially more powerful hyper-heuristics. For example, ExampleHyperHeuristic3.java shows how to implement a strategy which applies a mutation heuristic, followed by a local search heuristic, to the best solution from a memory of ten. It then chooses two random solutions, to which a crossover heuristic is applied. To apply a crossover heuristic, a different method is used requiring an extra argument. The indices of TWO solutions must be supplied to the method (the two parents). The offspring is placed into (or overwrites the solution at) the index in memory specified by a third parameter. It is possible to supply the index of a crossover heuristic to the method which applies a non-crossover heuristic. If this happens, the method will return the input solution unmodified. Therefore, the hyper-heuristic strategy implemented in ExampleHyperHeuristic1.java occasionally chooses a crossover heuristic which does nothing, as it is applied with only one input solution.It is possible that a problem domain may not contain any low level heuristics of a certain type. Therefore, before using a given heuristic type, it is important to check that a heuristic actually exists of that type for the problem domain which is currently being operated upon. ExampleHyperHeuristic3.java shows how to do this. If these checks are not put in place, then it is possible that your hyper-heuristic will not function correctly, as a Java NullPointerException will occur.
[Top]
'Depth of Search' and 'Intensity of Mutation'
The low level heuristics within each problem domain can be modified to a limited extent through the use of the 'Depth of Search' and 'Intensity of Mutation' parameters. These can be accessed through the 'get' and 'set' methods within the problem domain. Changing the value of one of these variables modifies the behaviour of all low level heuristics for all their subsequent executions (until modified again). The variables can be modified as often as is necessary, for example, they can be modified after every call to a low level heuristic. Their meaning depends on the heuristic in question, and the problem domain in question.Depth of Search only affects heuristics of the 'local search' class. It specifies the extent to which a local search heuristic will modify the solution. It is related to the number of improving steps to be completed by the local search heuristics.
Intensity of Mutation only affects heuristics of the 'mutation' or 'ruin-recreate' classes. It specifies the extent to which a mutation or ruin-recreate low level heuristic will change the solution. For a mutation heuristic, this could mean the range of new values that a variable can take, in relation to its current value. It could mean how many variables are changed by one call to the heuristic. For a ruin-recreate heuristic, it could mean the percentage of the solution that is destroyed and rebuilt. For example, a value of 0.5 may indicate that half the solution will be rebuilt by a RUIN_RECREATE heuristic.
Last Updated: 31 May 2011.